Postopek #
Zbiranje podatkov #
Raziskava se osredotoča na koncentracijo medijev v različnih sektorjih (tisk, televizija, radio in splet) v Sloveniji ter razkrivanju lastniških povezav tako regionalnih kot globalnih medijskih podjetij. Za oblikovanje vzorca medijev, ki je služil kot izhodišče za raziskovanje lastniških povezav, smo vključili medije iz sektorjev tiska, televizije in spleta, ki presegajo prag 3% dosega občinstva. Podatke o dosegu občinstva v Sloveniji zbirajo tri različne agencije, ki izvajajo standardizirane meritve: Mediana za branost tiskanih medijev, AGB Nielsen za gledanost televizije in MOSS za obisk spletnih medijev. Osnovni vzorec temelji na medijih, in ne, kot je bolj pogosto, na medijskih podjetjih, saj lahko posamezen izdajatelj ali podjetje oddaja, tiska ali pa ima v lasti več različnih medijev.
Po oblikovanju izhodiščne podatkovne baze smo izdajatelje posameznih medijev identificirali s pomočjo nacionalnega registra Razvid medijev Ministrstva za kulturo Republike Slovenije. Za zagotovitev točnosti podatkov smo uporabili orodje Wayback Machine, s katerim smo izdajatelja za leto 2022 preverili na spletni strani posameznega medija. V zadnjem koraku smo zbrali podatke o lastniških deležih izdajateljev, ki smo jih pridobili iz podatkovne baze GVIN, korporativne baze, ki podatke pretežno črpa iz AJPES-a, s katerim upravlja Agencija Republike Slovenije za javnopravne evidence in storitve.
Viri podatkov #
-
Doseg tiskanih medijev: Mediana (dostopano 1. feb. 2024 – 29. feb. 2024)
Vir: https://www.mediana.si/aktualni-podatki-o-branosti-tiskanih-medijev-mediana-tgi-2022/ -
Doseg spletnih medijev: MOSS, Merjenje obiskanosti spletnih strani (dostopano 1. feb. 2024 – 29. feb. 2024)
Vir: https://www.moss-soz.si/rezultati/ -
Doseg televizijskih programov: AGB Nielsen medijske raziskave (podatki so vključevali seznam TV-programov, ki so presegali prag 3% in ne natančnih podatkov o dosegu) (dostopano 11. mar. 2024)
Vir: https://www.nielsen.com/about-us/locations/slovenia/ -
Podatki o izdajateljih medijev: Razvid medijev (dostopano 29. feb. 2024 – 31. mar. 2024)
Vir: https://remk.ekultura.gov.si/razvid/mediji -
Lastništvo NTV24.si, d. d.: eBonitete (dostopano 31. mar. 2024)
Vir: https://www.ebonitete.si/ -
Podatki o podjetjih (prihodki, število zaposlenih, direktorji, lastništvo podjetij): GVIN (dostopano 1. feb. 2024 – 15. dec. 2024)
Vir: https://gvin.com
Urejanje podatkov #
Zbrane podatke je bilo treba za potrebe mrežne analize mestoma dodatno prečistiti in (pre)urediti. Koda uporabljena v ta namen (pa tudi za kalkulacije) je objavljena v repozitoriju Mirovnega inštituta.
Večina operacij se nanaša na združevanje ločenih tabel, standardizacijo neobstoječih podatkov ter preimenovanje spremenljivk za obdelavo v programu Gephi (in Networkx).
Lastniške deleže nižje od 1% smo zavoljo jasnejšega prikaza z Gepihijem in Retino zaokrožili na 1%. Večji maksimalen razpon (recimo 0,1% - 100%) med najmanjšim in največjim lastniškim deležem je proizvedel povezave med vozlišči, ki so bile na eni strani pretanke nad drugi pa predebele za branje omrežja.
V primerih, ko je bilo iz podatkovnih baz razvidno, da nekdo je lastnik, ne pa tudi kakšen je njegov delež, smo lastniški delež nastavili na 25%.
V EUR izraženi proračuni podjetij so bili s pomočjo podatkov/kalkulatorja SURS preračunani na vrednosti iz leta 2025.
Analiza in kalkulacije #
S Python knjižnico Networkx smo izvedli osnovne kalkulacije s področja mrežne analize - degree, in-degree, out-degree.
Prikaz širjenja vpliva po omrežju #
Osnovne kalkulacije temeljijo na povezavah z neposrednimi sosedi, kar v omrežjih, kjer je lastništvo organizirano posredno, tj. prek verige podjetij, predstavlja pomanjkljivost.
Da bi poudarili daljše verige vpliva, smo izvedli naprednejše kalkulacije. Te so na primeru kumulativnih out-degree vrednosti pojasnjene v poglavju o omrežjih.
Poleg kumulativnega out-degree, smo izračunali tudi kumulativne proračune in kumulativni doseg (za spletne in tiskane medije). Gre za to, da lastniki po lastniških verigah “dedujejo” proračune in doseg medijev v njihovi lasti. Te vrednosti so uravnotežene z lastniškim deležem - lastnik 10% medija torej pod vrednostjo cum_turnover akumulira 10% proračuna.
V spodnjem primeru Dnevnik, d.d. akumulira doseg in proračune medijev, ki jih ima v lasti neposredno in posredno skozi podjetje Primorske novice ČZD d.o.o.. Nadalje si Delo prodaja, DZS in DZS investicije (lastniki Dnevnika) na podlagi lastniškega deleža razdelijo skupen doseg (cum_national_net_reach) in proračun (cum_turnover) Dnevnik, d.d..
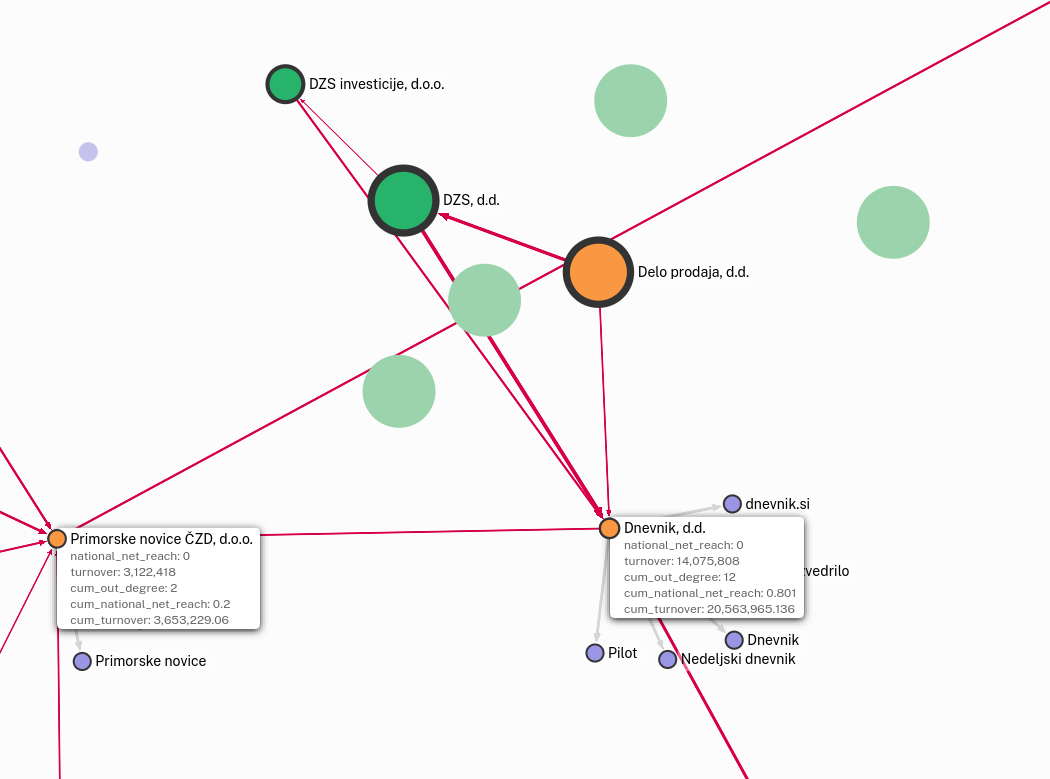
Koda s katero smo izvedli te kalkulacije je v celoti objavljena tu, spodaj pa prilagamo bistven del.
def calculate_degree_sums(
edges_df,
nodes_df,
property_col_name="Out-Degree",
output_column_prefix="degree",
output_file_path="updated_nodes.csv",
return_updated_df=False,
write_to_file=False,
max_depth=None,
weight_col=None, # edges_df
):
"""
Calculate the sum of specified properties up to a certain degree for nodes in a network.
Parameters:
- edges_df: DataFrame containing the edges of the network with 'source' and 'target' columns.
- nodes_df: DataFrame containing the nodes of the network with 'id' and specified property columns.
- property_col_name: Column name in nodes_df to sum for neighbors.
- output_column_prefix: Prefix for the output columns in nodes_df.
- output_file_path: File path to save the updated nodes DataFrame if write_to_file is True.
- return_updated_df: If True, return the updated nodes DataFrame.
- write_to_file: If True, save the updated nodes DataFrame to a CSV file.
- max_depth: Follow outgoing connections for max_depth number of degrees. If None, the code runs till the end of all outgoing connections.
Returns:
- Dictionary of summed properties for each node or the updated DataFrame if return_updated_df is True.
"""
if not {"source", "target"}.issubset(edges_df.columns):
raise ValueError("Edges file must contain `source` and `target` columns.")
if not {"id", property_col_name}.issubset(nodes_df.columns):
raise ValueError(f"Nodes file must contain `id` and `{property_col_name}` columns.")
nodes_df[property_col_name] = pd.to_numeric(nodes_df[property_col_name], errors="coerce").fillna(0)
property_dict = nodes_df.set_index("id")[property_col_name].to_dict()
degree_property_sums = {node: property_dict.get(node, 0) for node in nodes_df["id"]}
for node in nodes_df["id"]:
visited = set()
visited.add(node) # Mark the starting node as visited
queue = deque([(node, 0)]) # (node, current_depth)
while queue:
current_node, current_depth = queue.popleft()
if max_depth is not None and current_depth > max_depth:
continue
# Add neighbors to the queue and process the edge weights
neighbors = edges_df[edges_df["source"] == current_node]
for _, neighbor_row in neighbors.iterrows():
neighbor = neighbor_row["target"]
weight = neighbor_row.get(weight_col, 1) # Default weight is 1 if not specified
if neighbor not in visited and (max_depth is None or current_depth + 1 <= max_depth):
degree_property_sums[node] += property_dict.get(neighbor, 0) * weight
visited.add(neighbor)
queue.append((neighbor, current_depth + 1))
if return_updated_df:
output_column_name = f"{output_column_prefix}_{property_col_name}"
nodes_df[output_column_name] = nodes_df["id"].map(degree_property_sums)
if write_to_file:
nodes_df.to_csv(output_file_path, index=False)
print(f"Degree property sums calculated and saved to {output_file_path}")
return degree_property_sums if not return_updated_df else nodes_df